
{kind=link}
Anyone who has worked in .NET for a while runs into certain inconsistencies in the built-in collection interface types. The fundamental problem
is that there are multiple instances of the Count property. Nevermind that in .NET, the array types (including String) use Length instead; that's not
at issue here. Rather, note that in the .NET interface hierarchy there are at least three disjoint versions of the Count property which do
not unify.
For those who want to skip the discussion, here is a summary table which shows the collection interfaces implemented by the .NET built-in collection types along with the interfaces they implement. The table is organized so that the built-in collection types are divided into three groups according to which interface's Count property they implement. Cyan text indicates covariant or non-generic interfaces, and red blocks show the missing cases that should have been provided. (Click on the image for a larger version).
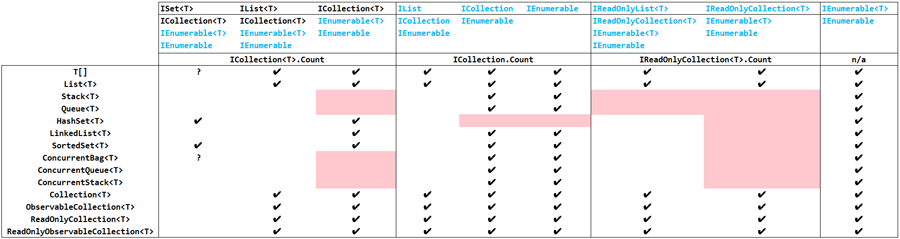
Logically compatible interfaces which do not unify are a general hazard in complex apps where classes are layering multiple collection interfaces with a goal of maintaining covariance. Covariance is the ability to assign strongly-typed instances of the collection to a collection interface type whose element type is more general. For example, the ability to assign a List<String> to a IEnumerable<out String>. It's the 'out' keyword in the interface declaration which enables covariance. Non-generic interfaces are naturally covariant since they do not have an element type (or, if you prefer, because their element type is infinitely general, that is, Object.
You'd think that having a single canonical property for the cardinality of a collection--regardless of whether the collection is ordered, distinct, lazy, empty, fixed-length, built-in or user-defined--would be simple, and in fact it is. Just for the record, the problems described here could largely be eliminated by creating a simple, non-generic base interface with a single member:
If covariant collections are important to your application, managing this mess in your own code is non-trivial. The covariant interfaces in .NET 4.5 are a godsend. I recommend using them wherever possible. But even here, opportunites were missed: many existing BCL classes were not retrofitted with these new interfaces, and the interfaces themselves did not adopt the non-generic Count property that they could have. That particular decision could be seen as complicating the landscape even further.
For those who want to skip the discussion, here is a summary table which shows the collection interfaces implemented by the .NET built-in collection types along with the interfaces they implement. The table is organized so that the built-in collection types are divided into three groups according to which interface's Count property they implement. Cyan text indicates covariant or non-generic interfaces, and red blocks show the missing cases that should have been provided. (Click on the image for a larger version).
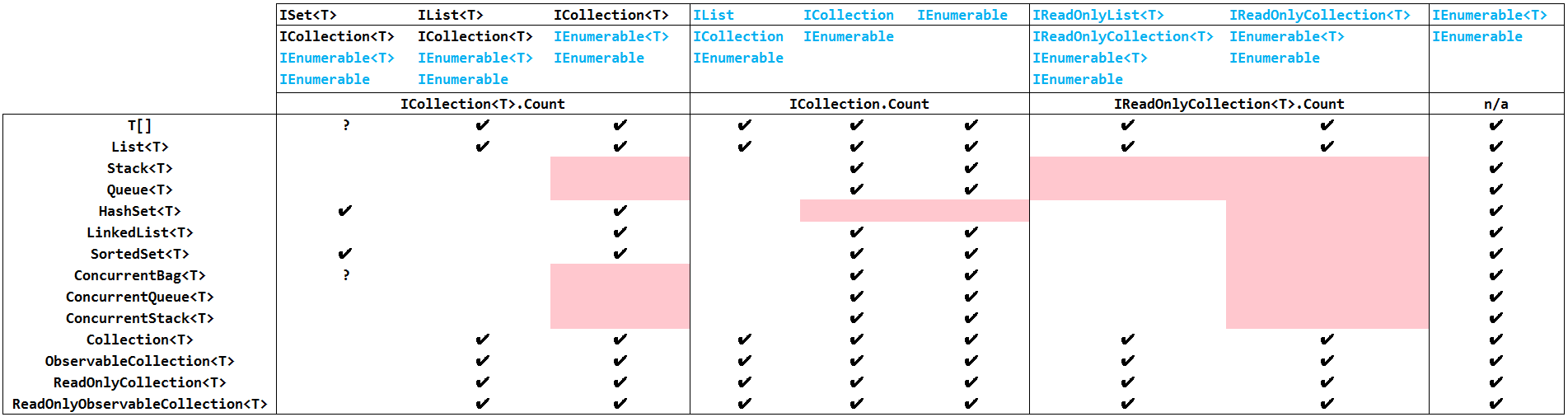
Logically compatible interfaces which do not unify are a general hazard in complex apps where classes are layering multiple collection interfaces with a goal of maintaining covariance. Covariance is the ability to assign strongly-typed instances of the collection to a collection interface type whose element type is more general. For example, the ability to assign a List<String> to a IEnumerable<out String>. It's the 'out' keyword in the interface declaration which enables covariance. Non-generic interfaces are naturally covariant since they do not have an element type (or, if you prefer, because their element type is infinitely general, that is, Object.
You'd think that having a single canonical property for the cardinality of a collection--regardless of whether the collection is ordered, distinct, lazy, empty, fixed-length, built-in or user-defined--would be simple, and in fact it is. Just for the record, the problems described here could largely be eliminated by creating a simple, non-generic base interface with a single member:
public interface ICount
{
int Count { get; }
};
Being non-generic, this interface would not affect the co- or contra-variance of its inheritors. Ideally, all generic and non-generic collection interfaces would inherit the Count property from here, so you would be guaranteed that they refer to the same thing. Alas, this is not the state of affairs:
-
Although IList implements ICollection--meaning they share the same Count, neither IList<T> nor ICollection<T> implements ICollection, which entails that their Count properties are disjoint.
This was probably done because ICollection contains several ugly, deprecated members (SyncRoot, IsSynchronized, etc.) which the later designers didn’t like. Those pollutions are still ugly today, but having disjoint Count properties--which relates to actual program correctness--is a worse problem. Perhaps the designers thought that generic interfaces would fully supplant non-generics, but this utopian vision ignores the need for backwards compatibility. And sure enough, along came WPF which wanted everything to be a non-generic IList. - For read-only use cases, ICollection<T> and IList<T> are bloated. This is owing to their Add/Insert/Remove API and also because of a new set of useless members they introduced. Neither interface can be covariant, of course.
-
You cannot implement your own collection interfaces to fix these problems for two reasons. First, your interface would not be implemented by the built-in collection classes.
Secondly, we especially want our collection interfaces to be covariant to the System.Array built-in type, and there is no way to author an interface such that it can be directly assigned by any array, regardless of strong-typing or covariance.
public interface IMyList<out T> : ICount { /// ... }; /// ... IMyList<Object> foo = new Object[1]; /// error error - In .NET 4.5, new lightweight, covariant collection interfaces were introduced. IReadOnlyCollection<out T> and IReadOnlyList<out T>. These new interfaces could have incorporated their Count property--without losing covariance--from the non-generic ICollection by inheriting that interface. Instead, for mysterious reasons (except perhaps to avoid those ugly members), these new covariant interfaces introduced yet another disjoint Count property, bringing the total to three.
- For unknown reasons, Stack<T> and Queue<T> do not implement ICollection<T>. This places them in the group of classes that use the non-generic ICollection.Count.
- On the other hand, HashSet<T>, only implements the generic ICollection<T>.Count. Could this be the influence of ISet<T>, for which there is no non-generic version?
- List<T> and the System.Collections.ObjectModel/Observable classes get the good citizen awards. They implement all three collection interfaces (including the new covariant ones) and correctly provides a consistent, unified Count property. Sadly, neither Stack<T>, Queue<T>, nor HashSet<T> implement IReadOnlyCollection<out T>.
- In general, concurrent collections might be exempted from this discussion, since the information obtained from a simple scalar property such as Count guarantees nothing about its value. But I included these collections in the table for completeness.
If covariant collections are important to your application, managing this mess in your own code is non-trivial. The covariant interfaces in .NET 4.5 are a godsend. I recommend using them wherever possible. But even here, opportunites were missed: many existing BCL classes were not retrofitted with these new interfaces, and the interfaces themselves did not adopt the non-generic Count property that they could have. That particular decision could be seen as complicating the landscape even further.
Drivers August 3, 2010 Adaptec AHA-2940 PCI SCSI driver for 64-bit Vista (x64)/Windows 7 (x64)
Intel 82852/82855 GM/GME mobile display drivers for 32-bit Vista (x86) (XDDM) and perhaps 32-bit Windows 7 (x86)
Top books January 23, 2010
Welcome January 3, 2010 Welcome to my redesigned personal website!
Winter break at the UW now comes to a close. I was able to get a lot done during the two-and-a-half weeks, and even took breaks for skiing and an evening trip to the Warehouse rock gym in Olympia, but my main project, which was to upgrade DBEdit, ended up taking much longer than expected.
DBEdit is the custom-built editing application for the thai-language.com lexicon. The current version is a C++/Win32 application version that dates back to 2000. It incorporated a statically-linked component called 'DBManager' to manipulate the in-memory database. For many years, the 'reading' half of DBManager's functionality was used by the production website to render webpages as well. At first this was achieved through a COM interface. When Microsoft introduced .NET to the server platform, the DBManager COM object was wrapped with a .NET assembly wrapper. Finally, about two years ago, the database reading functions were rewritten in C#.
However, this fork between the C++ and C# versions--the two shared only a common on-disk file format--caused development to become blocked by parallel code maintenance concerns.
So, my task over the past few weeks was two-fold: First, database writing capability had to be added to the C# code, and second, DBEdit had to use these new routines to manipulate the database. To do so, it would have to use the mixed-mode feature of the C++/CLI language. Mixed-mode allows a program to include both native C++ and managed C# code. This was important because DBEdit has thousands of lines of user-interface code that would take too long to rewrite.
Ripping DBManager out of DBEdit was easy. I created empty stub functions in the header file, and made sure that the program still compiled. That's where I stood an hour into the project, not knowing there would be a few hundred to go. Perhaps a clue should have been that there the header file of empty stub functions was 3700 lines long. Next, I used Visual Studio code analysis features to eliminate functions that were not needed. To the remaining stubs, I added a C++ 'throw' statement, and began a tedious cycle of running DBEdit, to see where it would halt, telling me what the "next" function I had to port over was.
Pretty quickly, I had the first screen up, using the managed C# back-end. However, booting the program to that point did not require any database writing, and I had already known that the reading part of the managed code worked. However, having gotten the program to boot and prove the concept of my mixed-mode vision, I now started to move away from the idea of keeping all my changes coralled in the stub file: I now felt comfortable with abandoning the ability to compile DBEdit the old way, and I started putting managed C++/CLI code directly in DBEdit.
As I mentioned, it may have taken as much as 300 hours to finish the job. I had to be extra paranoid with the database writing code, since bad code here would introduce corruption into the database, possibly ruining my website's most valuable asset. Testing the new version is now ongoing and my assistant in Phuket, David, has been invaluable in this.